
The 5 Best Text to Voice Converters: Unleashing the Power of the Text
Summary: Text to voice converter, with its powerful practicality, not only broaden channels of traditional reading but also enriches people's lives and work in multiple dimensions. It has become a useful tool in modern life.
- • Simplifies the process of adding text, images, and other elements to your text.
- • User-friendly interface for designing and formatting books without needing extensive technical knowledge.
- • Offers a wide selection of voices, featuring 20 unique male and female options for both English and Japanese.
- • Allows full customization of your audio with adjustable Prosody, Expressivity and Silence settings.
In today’s fast-paced world, text to voice app has become essential for multitaskers and learners. Whether you want to create audiobooks, boost accessibility, or simply enjoy listening to articles and documents, a right text to voice generator can make a difference. Here’s a introduction of five top text-to-voice apps, each has unique features to meet your needs.
Text to Voice: How Does It Work?
Text to voice ai, also known as text-to-speech (TTS), converts written text to speech voice using various techniques. Here’s a process of how it works:
- Text Input: The process begins when the user inputs text into the text to voice converter. This can be done by typing directly into the application, uploading a document, or pasting text from another source.
- Text Processing: Once the text is input, the software processes it to understand the structure and meaning. This involves several steps:
- Tokenization: The text is devided into smaller units, such as words or phrases.
- Normalization: The software converts numbers, abbreviations, and special characters into a readable format (e.g., converting "3" to "three").
- Phonetic Transcription: The software then translates the processed text into phonetic representations, determining how each word should be pronounced based on linguistic rules and context.
- Prosody and Intonation: text to voice systems analyze the text to add appropriate intonation, stress, and rhythm to speech. This involves setting parameters such as pitch, volume, and pauses to make the speech sound more natural.
- Voice Synthesis: Using advanced algorithms, the TTS system generates the audio output.
- Concatenative Synthesis: Pre-recorded speech segments (phonemes) are combined to form complete sentences.
- Formant Synthesis: Artificially generates sound waves to create speech without recorded samples.
- Neural TTS: Utilizes deep learning models to produce highly realistic and human-like voices.
- Audio Output: Finally, the synthesized voice is played back through speakers or headphones, allowing the user to listen to the text.
Text to Voice Process: Requirements for Text Input
When using text to audio software, certain requirements and best practices for text input can enhance the accuracy and quality of the output. Here are some key factors.
-
Text Format:
- Plain Text: Most text to voice applications prefer plain text well. Avoid complex formatting unless the software supports it.
- Clear Structure: Use paragraphs, headings, and bullet points to make your text more readable.
-
Language Compatibility:
- Supported Languages: Ensure that the text is in a language supported by the text to voice app. Some tools may not support your source or target languages.
-
Character Encoding:
- UTF-8 Encoding: Use UTF-8 encoding for text files to avoid issues with special characters or symbols that may not be recognized by the software.
-
Correct Spelling and Grammar:
- Proofread: Ensure that the text is free of spelling and grammatical errors. Incorrect spelling can lead to mispronunciations.
-
Punctuation:
- Proper Use of Punctuation: Use punctuation marks appropriately to guide pauses and intonation in the spoken output.
-
Clarity:
- Avoid Ambiguities: Choose words that are clear and unambiguous. For instance, consider how homographs (words that are spelled the same but have different meanings) may be interpreted.
-
Abbreviations and Numbers:
- Expand Abbreviations: Consider spelling out abbreviations or providing context, as text to voice software may misinterpret them (e.g., "Dr." as "Doctor" or "Drive").
- Formatting Numbers: Write numbers clearly, using words for small numbers (e.g., "three" instead of "3") when necessary for clarity.
-
Length of Text:
- Manageable Length: Keep the input text at a reasonable length. Very long passages may need to be broken into smaller segments to ensure proper processing.
-
Voice Selection:
- Contextual Considerations: If the TTS software allows voice selection, choose a voice that matches the tone and context of the text (e.g., formal vs. casual).
Top 5 Best Text to Voice APPs to Let Text Read to You
BookFab AudioBook Creator
BookFab AudioBook Creator offers high-quality, personalized text to voice conversion, making it easy to create lifelike audio. With a diverse selection of voices and extensive control over audio parameters, it is ideal for authors, content creators, and educators producing audiobooks, podcasts, or narrated articles. BookFab AudioBook Creator is a versatile text to voice generator.
- High-Quality AI Text-to-Speech: Delivers lifelike audio with unlimited downloads.
- Wide Selection of Voices: Offers 20 unique voices for both English and Japanese, with male and female options available. Voice cloning will be introduced in future updates.
- Customizable Voices: Full control over prosody, expressivity, and silence settings, allowing users to adjust speed and loudness for tailored audio.
- Pronunciation Correction: Features alias settings for replacing pronunciations and customizable reading rules for specific needs.
- Synchronous Highlighting and Automatic Scrolling: Real-time text highlighting as audio plays, with the ability to select specific sentences for playback.
- Flexible Input and Output: Supports direct text input or TXT file imports, with audio output in multiple formats (text to MP3, OPUS).
- High-quality and realistic audio output.
- Extensive voice options and customization.
- User-friendly interface with interactive features.
- Limited language options (primarily English and Japanese).
How to Use BookFab AudioBook Creator
Step 1: Launch the BookFab Client and Input Your Text
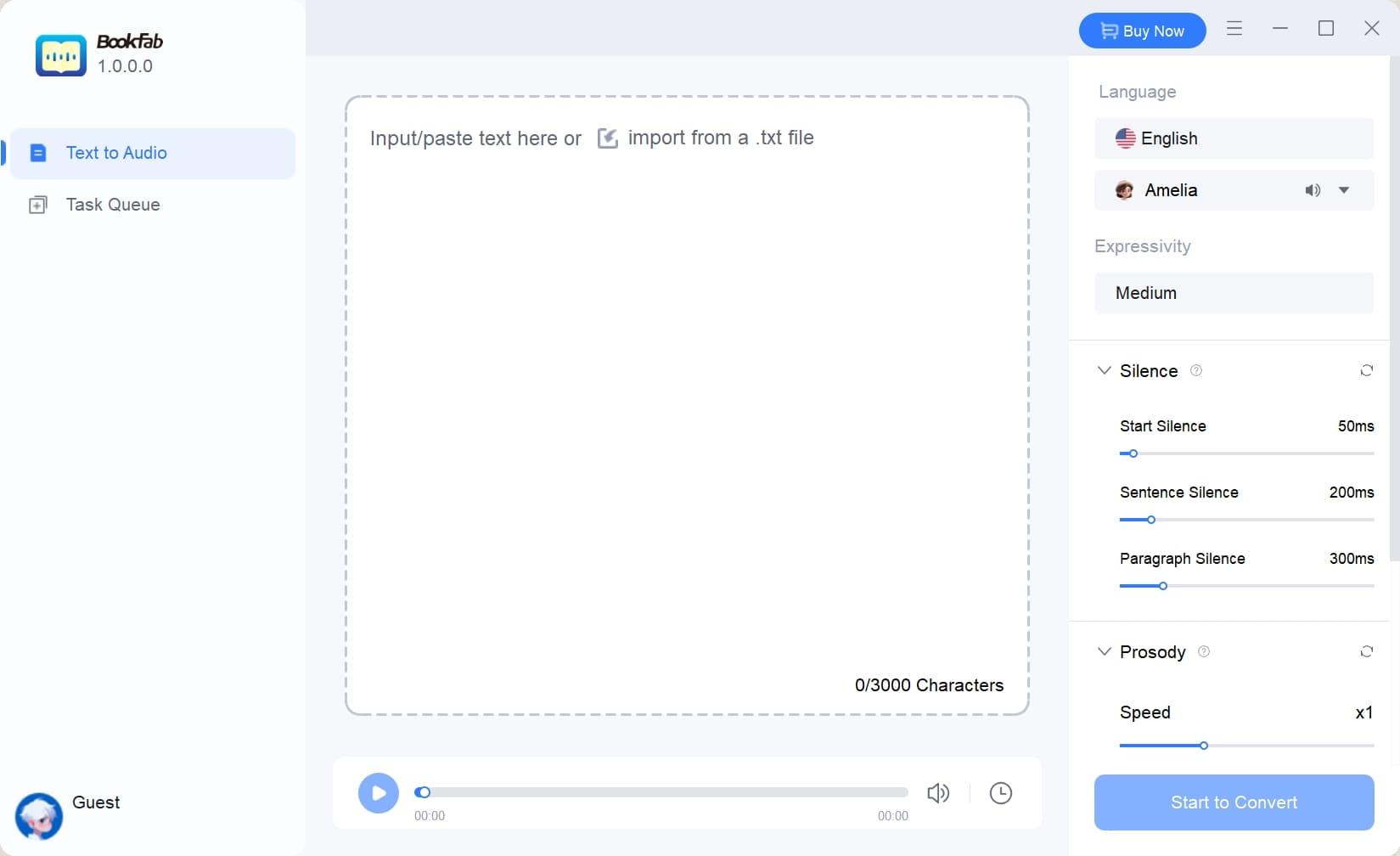
Open the BookFab client on your computer and either paste text into the main interface or import a .txt file.
Step 2: Choose and Customize the Voice
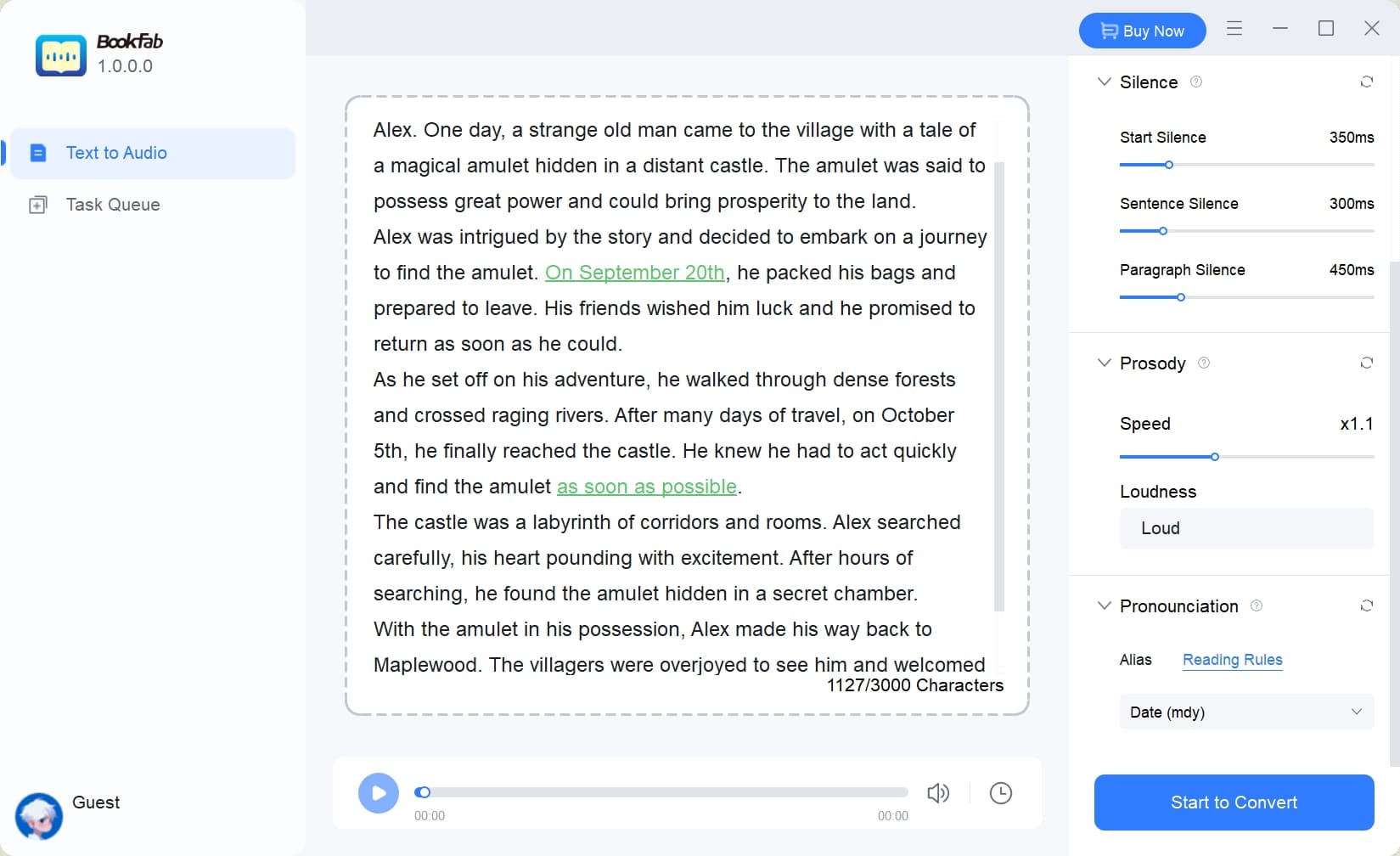
Select the desired language and voice, then adjust settings such as speed, pitch, loudness, silence and emotional expression to your preference.
Step 3: Convert Text to Speech and Play the Audio
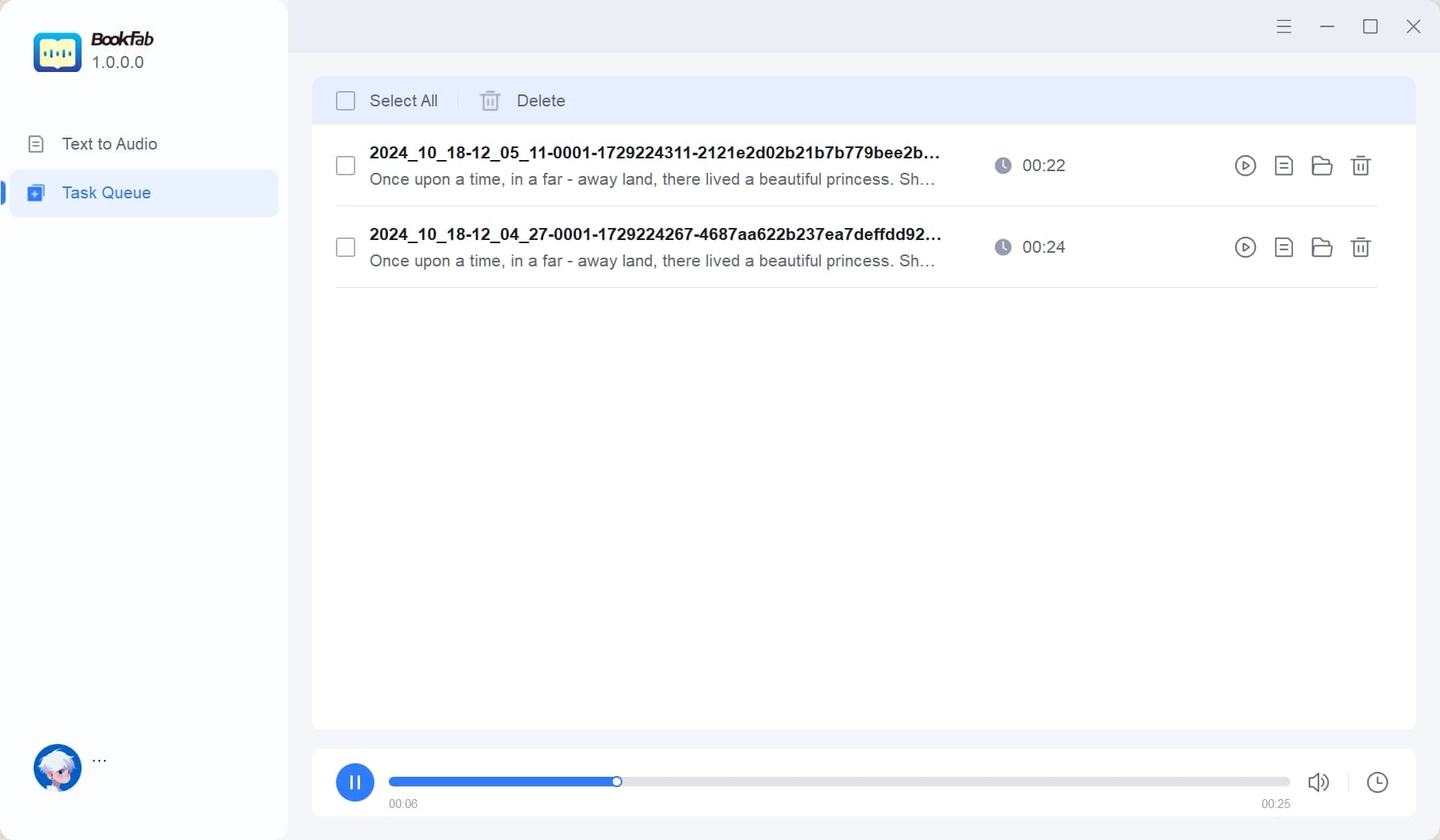
Start to convert your text to speech. Once the conversion is completed, you can play the natural-sounding speech online or check the downloaded audio file.
Speechify
Speechify is a leading AI voice generator renowned for its versatility and high-quality audio output. Available across all major platforms—Android, iOS, Windows, Mac—and popular web browsers, Speechify utilizes advanced machine learning and AI technology to deliver natural-sounding speech. It’s particularly beneficial for e-learning, auditory learners, and individuals with reading disabilities, offering both a free and a excellent version.
- Cross-Platform Compatibility: Works on Android, iOS, Windows, Mac, and major web browsers (Chrome, Safari, Firefox).
- Natural-Sounding Voices: Offers customizable voices, including unique celebrity voices.
- OCR Technology: Converts physical documents into audio using optical character recognition.
- Intuitive User Interface: Simple and user-friendly process for seamless operation.
- Productivity Enhancements: Ideal for multitasking, allowing users to listen to content while on the go.
- High-quality, natural-sounding audio.
- Wide range of voice options, including celebrity voices.
- Effective OCR capabilities for converting printed text to speech.
- Available as a free app with an optional premium version for advanced features.
- Some advanced features may require a premium subscription.
- The effectiveness of OCR can vary depending on the quality of physical documents.
Murf.AI
Murf.AI is a powerful text to voice converter that offers over 100 distinct voices, making it an excellent choice for narration and content creation. Known for its robust customization options and natural-sounding audio, Murf.AI elevates audio content beyond basic text conversion. However, the free version has limitations, offering only ten minutes of usage without download capabilities.
- Natural-Sounding Voices: Quality-checked to ensure elimination of robotic tones for more human-like audio.
- Highly Customizable: Users can control pitch, pauses, and pronunciation, allowing for a tailored listening experience.
- Multi-Language Support: Includes a selection of voices in 20 different languages, enhancing accessibility.
- Exceptionally high-quality, human-like voice output.
- Extensive customization options for precise control over audio delivery.
- Versatile use cases, suitable for corporate presentations, entertainment, and more.
- The free version is limited, which may not suit all users.
- Customization features may require a learning curve for optimal use.
Read Aloud
Read Aloud is a convenient text-to-speech extension for Google Chrome that reads aloud the content of the currently open webpage. Supporting 40 languages, this tool is versatile and effective for various online texts. Its simple design and easy installation make it a valuable resource for users looking to listen to web content effortlessly.
- Browser Extension: Can be easily installed on Google Chrome for quick access.
- Multi-Language Support: Supports 40 different languages, accommodating a wide range of texts.
- User-Friendly Design: Simple and intuitive interface for easy operation.
- Convenient for reading web pages aloud in real-time.
- Supports a large number of languages, enhancing accessibility.
- Lightweight and easy to use as a browser extension.
- Limited to the content of the currently open page; cannot process offline documents.
- May not offer advanced features compared to dedicated text to voice software.
Voicemaker
Voicemaker is a sophisticated tool designed to transform text into customized voice outputs. It offers various options for voice personalization, allowing users to explore over 1,000 AI voices with high audio quality. This text-to-speech converter supports AI voices in more than 130 languages.
- Extensive Voice Library: Offers over 1,000 AI-generated voices in various accents and styles.
- Multi-Language Support: Provides text-to-speech capabilities in more than 130 languages.
- Customization Options: Allows users to adjust pitch, speed, and volume for personalized audio output.
- Audio Formats: Supports multiple audio formats for export, including MP3 and WAV.
- Text Highlighting: Includes features for real-time text highlighting while reading, enhancing user engagement.
- API Access: Offers an API for developers to integrate TTS functionality into their applications.
- High-Quality Audio: Produces natural-sounding speech, making it suitable for professional use.
- User-Friendly Interface: Easy to navigate, making it accessible for users of all skill levels.
- Versatile Applications: Ideal for content creators, educators, and businesses needing voiceovers.
- Free Tier Available: Offers a free version with basic features, allowing users to try before committing.
- High system requirements: Requires powerful hardware and high-speed internet for optimal performance, potentially limiting access for users with older systems.
- Complex interface navigation: The user interface may be overwhelming for beginners, with advanced features that require a learning curve to master effectively.
FAQs About Text to Voice
Yes, many TTS systems support multiple languages, though the number of supported languages and voice options varies by software.
Ensure proper spelling, grammar, punctuation, and clarity in the text. Avoid overly complex formatting and check that the software supports the language used.
Some TTS tools have OCR (optical character recognition) capabilities, allowing them to read printed documents or convert PDFs to speech.
Neural TTS uses deep learning algorithms to produce more natural and expressive speech compared to traditional methods. It mimics human speech patterns more closely.
Many TTS programs allow users to select from various voice options and adjust parameters like pitch, speed, and volume for a more personalized experience.
Final Thoughts
With a solid understanding of the text to voice software discussed above, you’ll be better equipped to choose the option that best meets your needs.However, Text to voice technology faces several challenges that can impact its effectiveness, including limitations in naturalness, pitch variation, emotional expression, and other aspects, technology is constantly advancing. Researchers and developers are working hard to address these issues and are exploring new methods and algorithms to further improve the performance and use.
 Find the 5 Best AI Voice Generators to Create Exciting Voiceovers in 2024
Find the 5 Best AI Voice Generators to Create Exciting Voiceovers in 2024Decoding what is the best AI voice generator can be crucial for creators new to this dubbing field. Whether in the post-production phase or a novice, finding and settling on the best text to speech AI voice generator can be daunting unless you read this article. Here, we have listed the best AI voice generator free text to speech, to simplify your job and save time.
Learn More Top 5 Tools to Effortlessly Convert Text to MP3 in 2024!
Top 5 Tools to Effortlessly Convert Text to MP3 in 2024!Convert text to audio MP3 using the best free converters to reduce eye strain. Leverage a variety of languages and natural human voices to enhance your online learning and listening experience, making content more engaging and accessible.
Learn More Top 5 Best Text to Audio Solutions of 2024
Top 5 Best Text to Audio Solutions of 2024This article reviews the top five text-to-audio solutions of 2024, emphasizing their features for enhancing accessibility and learning. It aims to help readers find the best tool for converting text to audio, facilitating effective communication and engagement.
Learn More How to Use Kindle Text to Speech: Windows, Mac, iOS and Android
How to Use Kindle Text to Speech: Windows, Mac, iOS and AndroidKindle Text to Speech is a great feature that helps you multitask and manage your time efficiently. In this article, you will see how to enable Text to Speech Kindle app and on PC/Mac.
Learn More